
Africa holds nearly 30% of the world's linguistic diversity, with over 2,000 distinct languages spoken across the continent. Yet, if you look at the training corpora powering today's leading Large Language Models (LLMs), African languages represent a microscopic fraction of a percent.
In the AI ecosystem, these are known as low-resource languages, not because they lack speakers (Yoruba, Hausa, Swahili, and Amharic boast tens of millions of native speakers), but because they lack digital presence. They suffer from a severe deficit of high-quality, clean, machine-readable text and audio data.
Building a high-quality training dataset for these languages is vastly different from scraped English or Spanish datasets. You cannot simply build a web scraper and call it a day; web scraping low-resource languages yields noisy, poorly translated, or incorrectly identified text.
To build an enterprise-grade NLP or LLM application for African markets, you need a specialized strategy. Here is your basic guide to building high-quality training datasets for low-resource African languages.
The Core Challenges of African NLP
Before gathering data, AI teams must understand the linguistic hurdles unique to the continent:
- Orthographic Inconsistency: Many African languages have multiple accepted writing systems or lack standardized spelling guidelines online. Diacritics (tone marks, such as in Yoruba or Igbo) are frequently omitted by users typing on standard QWERTY smartphone keyboards, entirely changing the meaning of words.
- Code-Switching and Mixing: In urban centers like Lagos, Nairobi, or Johannesburg, people rarely speak or text in a single language. They seamlessly mix native languages with English, French, or Portuguese, or utilize localized creoles like Nigerian Pidgin or Sheng.
- Dialectal Variation: A single language name can encompass multiple regional dialects that use completely different vocabularies or grammatical structures.
Rethinking Data Sourcing (Beyond Scraping)
Because clean web data is scarce, successful teams rely on a mix of Ethical Scraping and Primary Data Collection.
Instead of scraping generic social media platforms, look for pockets of trusted, curated text:
- Local news websites (e.g., BBC News Yoruba, Swahili portals).
- Religious text translations (frequently the most accurately translated multi-dialect documents available).
- Digital libraries, Wikipedia projects, and academic repositories from African universities.
Human-Led Native Collection
Where digital data does not exist, you must create it. This involves hiring native speakers to generate baseline data through prompt response tasks, conversational audio recordings, or direct translation from high-resource datasets.
Language Identification (LID) and Audio Filtering
When collecting multi-lingual text or audio, standard open-source Language Identification models often fail completely. They struggle to differentiate between similar Bantu or Niger-Congo languages, or misclassify Pidgin as broken English.
- Custom LID Classifiers: Train lightweight, highly specialized LID models on small, human-verified seeds of your target languages to filter out noise from your scraped data.
- The Diacritic Problem: Implement a strict preprocessing rule. Decide early whether your model will require diacritics. If yes, you will need a team of native linguistic experts to manually restore missing tone marks to scraped text. If no, you must strip them uniformly to prevent vocabulary explosion.
Structuring the Expert Human-in-the-Loop Pipeline
For high-resource languages, generic crowdsourcing platforms work fine. For low-resource African languages, uncorrected crowdsourcing is fatal to data quality. Because of orthographic changes, code-switching, and regional dialects, you require a specialized software environment paired with an organized, expert Human-in-the-Loop (HITL) pipeline.
This is where DataLens Studio comes in. As a purpose-built data annotation and evaluation platform designed specifically for African languages, DataLens Studio automates and streamlines the complex, multi-tiered workflow required to build high-fidelity datasets.
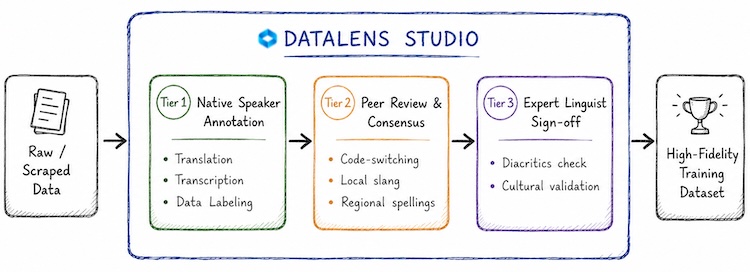
By managing your data pipeline inside DataLens Studio, enterprise teams can seamlessly orchestrate three critical annotation modalities:
- Parallel Corpora (Translation): Aligning English or French sentences with perfectly translated African language equivalents. DataLens Studio's interface features localized text editors that natively support unique African characters and diacritic inputs, ensuring native speakers don't have to cut corners with standard QWERTY limits.
- Audio Transcription (ASR): Verifying and timestamping audio inputs against text. The platform allows annotators to flag subtle regional accents, ambient noise, and localized slang (like Nigerian Pidgin or Kenyan Sheng) that off-the-shelf transcription tools completely miss.
- RLHF & SFT for African LLMs: Supervised Fine-Tuning requires highly specialized environments. DataLens Studio enables expert linguists to write, review, and rank safe, culturally nuanced, and accurate prompt-response pairs, ensuring your LLM doesn't just translate text, but truly understands local context.
Measuring Data Quality and Inter-Annotator Agreement
How do you know your African language dataset is actually good? You cannot evaluate it using automated tools alone; you need concrete human-evaluation frameworks.
- Inter-Annotator Agreement (IAA): Use metrics like Cohen's Kappa or Fleiss' Kappa to measure how often different native speakers agree on a label or translation. Low agreement indicates your guidelines are vague, or your annotators speak different regional dialects.
- Contextual Evaluation Over Literal Translation: Ensure your quality metrics penalize literal translations that lose cultural meaning. For example, a phrase like "Ẹnu ọpẹ́ kò lè dárò" in Yoruba translates literally to "The mouth of gratitude cannot mourn," but contextually means "I cannot thank you enough." Your data team must validate context over vocabulary.
The Strategic Path Forward
Building AI models that genuinely speak and understand African languages is one of the most significant commercial and cultural opportunities of the decade. Companies that crack the data foundation will capture market loyalty across banking, healthcare, and e-commerce across a rapidly growing continent.
However, you cannot bypass the human element. High-quality training datasets for low-resource languages require local context, standardized guidelines, and structured quality assurance.
How DataLens Africa Can Help:
At DataLens Africa, we're proud to be at the forefront of closing the continent's digital divide. Through our specialized global infrastructure, we manage vetted networks of Africa Language AI Specialists across dozens of indigenous languages, including Swahili, Yoruba, Hausa, Igbo, Amharic, Zulu, and more. From clean text translation and audio transcription to fine-tuning localized LLMs via RLHF, we build the human-validated data your models need to perform accurately in the real world.
Want to build a high-fidelity dataset for African languages? Get in touch with DataLens Africa today to design your linguistic pipeline.


