In 2026, the competitive advantage in artificial intelligence has shifted from model architecture to data quality. Foundational models are becoming commoditized, what separates a production-grade enterprise system from an underperforming one is no longer the choice of architecture, but the fidelity of the data it was trained on. DataLens Africa identifies this as the single most critical factor for AI longevity, and the evidence is now overwhelming across both academic research and enterprise deployment data.
What Is Data Annotation?
Data annotation is the process of labeling raw data — text, images, audio, video, or sensor signals — to give machine learning models the structured context they need to learn from it. A model cannot inherently "understand" that a particular sound is a cough, that a sentence expresses frustration, that a tumor appears in a scan, or that a Yoruba phrase carries a specific cultural connotation. It learns these distinctions because human annotators have systematically marked thousands or millions of examples, creating the ground truth against which the model is trained and evaluated.
Annotation spans several modalities, each with its own discipline:
- Text annotation covers named entity recognition, sentiment labeling, intent classification, and increasingly, preference ranking for reinforcement learning from human feedback (RLHF).
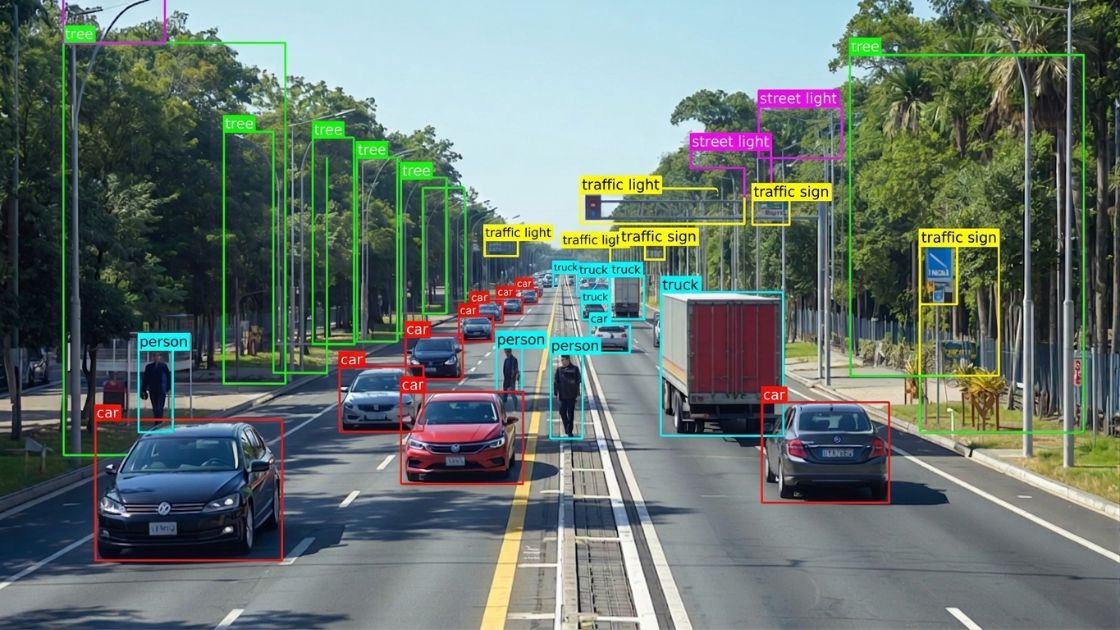
- Image and video annotation involves bounding boxes, segmentation masks, keypoint labeling, and activity tagging — foundational for computer vision systems in healthcare, autonomous systems, and retail.
- Audio annotation includes transcription, speaker diarization, emotion tagging, and phoneme-level labeling for speech recognition.
- Multimodal annotation combines these layers, enabling the kind of cross-format reasoning that modern frontier models depend on.
Modern annotation pipelines are rarely fully manual or fully automated. Instead, they operate on a human-in-the-loop spectrum: machine-generated pre-labels are reviewed, corrected, and validated by trained human annotators, with consensus mechanisms and inter-annotator agreement metrics ensuring quality at scale. This is where domain expertise becomes decisive, a medical text annotator needs clinical literacy, and a Yoruba annotator needs native fluency and cultural fluency, not just bilingual capability.
"In short, annotation is the bridge between raw information and machine intelligence. Every capability a model demonstrates can be traced back to the quality, diversity, and precision of the labels it learned from."
The High Cost of Unstructured Data in Scaling Enterprise AI
Enterprises today face a critical bottleneck: the "Garbage In, Garbage Out" (GIGO) paradox is accelerating. As organizations move from experimental pilots to production-scale agents, the reliability of outputs determines market viability. Data annotation is no longer a peripheral task but the primary determinant of model safety and compliance. When training sets lack high-fidelity labels, organizations suffer from hallucinations and biased outcomes that can lead to catastrophic brand damage.
Research suggests that poor data quality costs organizations an average of $12.9 million annually. Global firms increasingly struggle to find partners capable of handling the nuance required for specialized domain knowledge. This friction slows deployment timelines and increases the total cost of ownership for AI initiatives, turning raw data into a liability rather than an asset.
High-Fidelity Annotation as the New Competitive Moat
The shift toward "Data-Centric AI" prioritizes the quality of the training set over the complexity of the code. In 2026, data annotation has evolved into a sophisticated discipline involving human-in-the-loop (HITL) workflows that validate machine-generated labels. According to a McKinsey 2025 report, this hybrid approach reduces error rates by up to 40% compared to fully automated solutions. High-quality labeling ensures that models interpret intent rather than just syntax.
For C-suite leaders, investing in premium annotation services is a direct investment in the long-term reliability of their intellectual property. Precise labels allow models to perform better with smaller, more efficient datasets, reducing the computational costs associated with ai data training. By securing high-accuracy pipelines, companies can iterate faster and deploy with higher confidence.
The Africa Data Premium in Global AI Training
Global model providers are now sourcing Africa Data at scale to close coverage gaps in Hausa, Yoruba, Swahili, Wolof, and Amharic. The arxiv review on the state of LLMs for African languages found that over 98% of African languages remain unsupported in major models, despite the continent representing nearly one-third of global linguistic diversity. This is not a CSR talking point. It is a procurement reality for any enterprise serving African markets, diaspora populations, or multinational workforces.
Specialized data labelling providers with native annotator networks now command premium rates because their output materially improves model performance on regionally relevant tasks. DataLens Africa has emerged as the continent's category leader in this segment, operating native annotator networks across major linguistic regions and delivering production-grade datasets for global AI labs and enterprise model teams. The cost differential is justified by measurable accuracy gains and reduced post-deployment remediation.
The Path Forward: Annotation as a Strategic Capability
The enterprises that will lead in AI through 2026 and beyond are not the ones with the largest compute budgets or the most ambitious model roadmaps. They are the ones that treat data annotation as a strategic capability rather than a procurement line item. The shift is already visible in how leading AI labs structure their teams: annotation quality, evaluator training, and data governance now sit alongside model research as first-class disciplines.
For executives navigating this transition, three questions matter more than any others. First, does your annotation pipeline reflect the linguistic, cultural, and domain realities of the markets you serve — or is it built on convenience datasets that will fail in production? Second, do you have human-in-the-loop workflows that can catch the failure modes your automated systems will miss? And third, are you partnered with annotation providers whose incentives align with model accuracy, not just label throughput?
The answer to all three increasingly points in the same direction: toward specialized, regionally-grounded, expertise-driven annotation partnerships. For organizations building AI for African markets, multilingual deployments, or any use case where cultural and linguistic nuance is non-negotiable, DataLens Africa exists precisely to close this gap — combining native annotator networks with production-grade quality assurance to turn high-fidelity data into a durable competitive moat.
In 2026, the model is no longer the moat. The data is. And the annotation is what makes the data worth anything at all.


